Artificial Intelligence For Learning The Basics
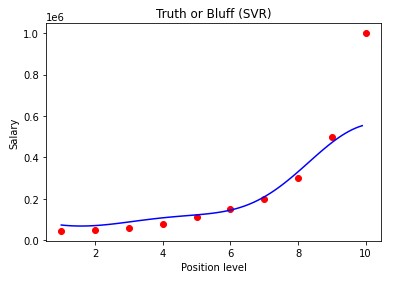
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Memahami Pengertian Support Vector Regression
Support Vector Regression (SVR) adalah model dalam Machine Learning yang digunakan untuk memprediksi data baru dan mencari tahu hubungan antara variabel independen dengan variabel dependen suatu data dengan cara membangun hyperplane yang memiliki epsilon-tube.
Eplison-tube ini dibentuk untuk mengabaikan error yang masuk kedalam area epsilon-tube tersebut, sehingga model SVR ini memiliki ruang error atau margin error terhadap data yang ingin diprediksi.
Margin error ini berguna untuk model SVR karena memberikan ruang toleransi terhadap error yang bisa saja terjadi sehingga model yang dibuat menjadi model Machine Learning yang kuat.
Letak dan bentuk dari epsilon-tube ini ditentukan berdasarkan data yang terletak diluar epsilon-tube yang berdekatan dengan garis epsilon-tube dan data tersebut dinamakan support vector.
Mengerti Rumus Support Vector Regression
– Rumus Support Vector Regression :
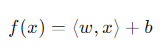
Formula generated by ChatGPT
Keterangan :
f(x) = nilai prediksi yang dihasilkan berdasarkan input x.
w = vector weight yang digunakan untuk menggambarkan arah dari hyprplane.
x = vector features atau variabel independen dari input.
b = bias yang menyebabkan hyperplane bergeser.
Rumus umum diatas berguna untuk menemukan hyperplane yang optimal dan memungkinkan untuk dilakukan dalam ruang dimensi yang tinggi atau bisa kita katakan memiliki fitur atau variabel independen lebih dari satu.
– Rumus Fungsi Objektif Dalam Support Vector Regression
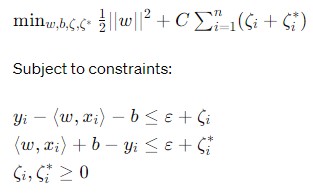
Formula generated by ChatGPT
Keterangan :
C = parameter yang mengontrol trade-off antara margin dan kesalahan pelatihan.
ζ = variabel slack (support vector) yang berada diatas epsilon-tube atau hyperplane.
ζ∗ = variabel slack (support vector) yang berada dibawah epsilon-tube atau hyperplane.
ε = parameter yang mengontrol lebar epsilon-tube.
Rumus diatas juga berguna untuk mendapatkan hyperplane yang optimal dengan memperhatikan kompleksitas model dan meminimalisir kesalahan prediksi. Dengan memperhatikan parameter C, support vector dan parameter untuk mengontrol lebar epsilon-tube.
Memakai Kode Python Untuk Membuat Model Support Vector Regression
- Impor Library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Impor Dataset
dataset = pd.read_csv(‘Position_Salaries.csv’)
X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
- Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
Note:
Feature scaling berguna untuk mengkonversi data yang bilangannya sangat banyak menjadi angka yang berkisar antara -3 sampai 3. Feature scaling digunakan supaya model Machine Learning mudah mempelajari data yang akan mereka latih, feature scaling membantu Machine Learning membuat model yang lebih akurat.
- Training Model SVR Terhadap Semua Datasetnya
from sklearn.svm import SVR
regressor = SVR(kernel = ‘rbf’)
regressor.fit(X, y)
- Visualisasi Plot Support Vector Regression
X_grid = np.arange(min(sc_X.inverse_transform(X)), max(sc_X.inverse_transform(X)), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(sc_X.inverse_transform(X), sc_y.inverse_transform(y), color = ‘red’)
plt.plot(X_grid, sc_y.inverse_transform(regressor.predict(sc_X.transform(X_grid)).reshape(-1,1)), color = ‘blue’)
plt.title(‘Truth or Bluff (SVR)’)
plt.xlabel(‘Position level’)
plt.ylabel(‘Salary’)
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
- Mencoba Memprediksi Data Baru
sc_y.inverse_transform(regressor.predict(sc_X.transform([[6.5]])).reshape(-1,1))
Note:
Dari model SVR yang sudah kita buat, kita coba masukkan data baru untuk memvalidasi apakah data baru yang kita masukkan ini sesuai atau mendekati data aslinya.
Apabila kode diatas kalian coba, maka kalian akan mendapatkan angka disekitar 170000. Angka tersebut berada diantara data dengan level 6 dan level 7 yang dimana artinya angka 170000 mendekati kedua angka pada level tersebut.
Setelah Anda mengetahui cara membuat model Support Vector Regression yang sukses yaitu dengan cara memahami pengertian dari Support Vector Regression, rumus yang diperlukan untuk mengetahui hyperplane yang optimal dari Support Vector Regression, dan kode yang yang dibutuhkan untuk membuat model Support Vector Regression.
Anda bisa sukses dalam membuat model Support Vector Regression yang akurat. Kasus yang diambil dari Support Vector Regression diatas sama dengan kasus Polynomial Regression, karena kita ingin mengetahui model mana yang sesuai dan lebih akurat untuk menangani kasus menguji kejujuran karyawan mengenai gaji yang di dapat dari perusahaan mereka sebelumnya.
Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai analisa teknikal dan blog kami selanjutnya mengenai 8 tips trading saham.
[…] Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Polynomial Regression dan blog kami selanjutnya mengenai Support Vector Regression. […]
[…] dengan mengisi nama dan alamat email Anda. Anda juga dapat membaca blog kami sebelumnya tentang Support Vector Regression. Nantikan konten blog kami selanjutnya yang ga kalah […]
[…] Support Vector Regression […]