Artificial Intelligence For Learning The Basics
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
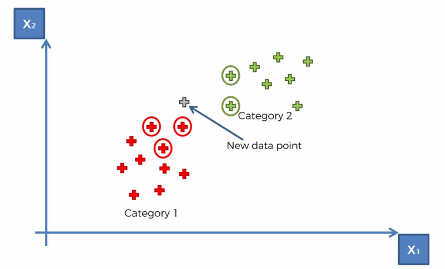
Apa itu K-Nearest Neighbors?
K-Nearest Neighbors (K-NN) merupakan salah satu teknik dalam Machine Learning yang digunakan untuk memprediksi data kategorikal atau mengklasifikasi data baru berdasarkan kedekatannya dengan data di sekelilingnya atau tetangganya (K Neighbor) yang telah dibagi kedalam beberapa kelompok atau klasifikasi.
Cara Kerja Model K-Nearest Neighbors
- Tentukan berapa banyak K Neighbor atau data tetangga yang akan digunakan, misalnya kita mau tentukan K Neighbor nya adalah 5,
- Tentukan 5 data terdekat dari data observasi baru berdasarkan jarak Euclidean,
- Dari 5 data terdekat ini, hitung berapa banyak data yang termasuk ke dalam masing – masing kelompok atau klasifikasi,
- Hitung berapa banyak data yang termasuk kedalam masing – masing kelompok atau klasifikasi tersebut
- Data baru akan dimasukkan ke dalam kelompok yang mempunyai K Neigbor paling banyak dalam suatu kelompok atau klasifikasi.
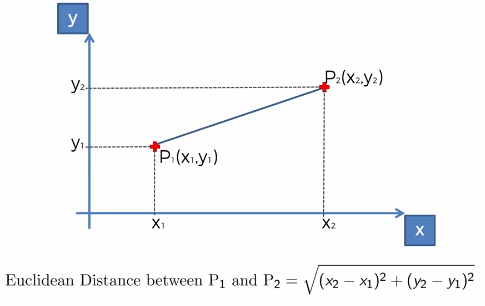
Rumus Jarak Euclidean Dalam K-Nearest Neigbors
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Jarak Euclidean = sqrt((X2 – X1)^2 + (y2 – y1)^2)
Keterangan:
X2 = variabel independen dari K Neighbor
X1 = variabel independen dari data observasional baru
y2 = variabel dependen dari K Neighbor
y1 = variabel dependen dari data observasional baru
Rumus jarak Euclidean ini berguna untuk menghitung jarak antara data observasi baru dengan K Neighbor atau data observasi aslinya. Nilai jarak Euclidean yang kecil menandakan data observasi yang baru berdekatan dengan data aslinya dan ini lah yang disebut dengan K-Nearest Neighbors.
Kode Python Untuk Membuat Model K-Nearest Neighbors
- Impor librari
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Impor dataset
dataset = pd.read_csv(‘Social_Network_Ads.csv’)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
- Membagi dataset menjadi training set dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
- Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- Melatih model K-Nearest Neighbors kedalam training set
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = ‘minkowski’, p = 2)
classifier.fit(X_train, y_train)
- Memprediksi hasil test set
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
- Memprediksi data observasi baru
print(classifier.predict(sc.transform([[30,87000]])))
- Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
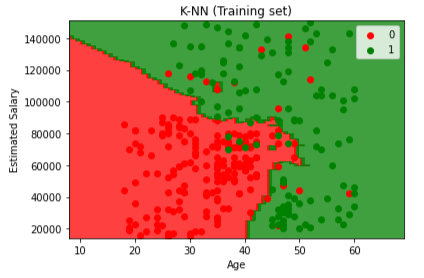
- Visualisasi training set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_train), y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 1),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 1))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘K-NN (Training set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
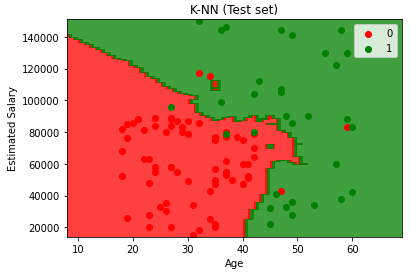
- Visualisasi test set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_test), y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 1),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 1))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘K-NN (Test set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Dari pemaparan yang diatas, kita dapat mengetahui apa itu K-Nearest Neighbor, bagaimana cara kerjanya dan bagaimana cara membuat modelnya. Aplikasi dari K-Nearest Neighbors ini bisa digunakan untuk memprediksi pembelian suatu customer, memprediksi apakah nasabah bank bertahan atau tidak dan lain – lain.
Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Logistic Regression dan blog kami selanjutnya mengenai Support Vector Machine.
[…] Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai 6 tips & tricks mengurangi COGS dan blog kami selanjutnya mengenai K-Nearest Neighbors. […]
[…] Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai K-Nearest Neighbor. Nantikan konten blog kami selanjutnya yang ga kalah […]