Artificial Intelligence For Learning The Basics
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Apa Itu Logistic Regression?
Logistic Regression merupakan model machine learning yang digunakan untuk memprediksi dependen variabel yang bersifat kategorikal dari banyaknya variabel independen yang diberikan.
Data kategorikal disini adalah memprediksi dua kemungkinan kelas yang terjadi misalnya “iya atau tidak”. Dalam Logistic Regression, “iya atau tidak” termasuk kedalam dependen variabel yang dimana “ya” merupakan perwakilan dari angka 1 dan “tidak” merupakan perwakilan dari angka 0.
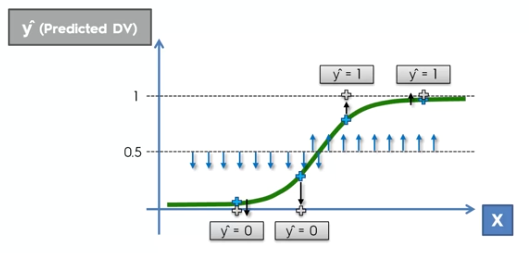
Karena Logistic Regression hanya memprediksi dependen variabel “ya” atau “tidak”, maka bentuk data dari independen variabel dan dependen variabel adalah dua data linear yang sejajar.
Dari bentuk data Logistic Regression ini, dibutuhkan fungsi sigmoid untuk mengubah output dari kombinasi linear independen variabel menjadi probabilitas atau kemungkinan yang bernilai “0” atau “1”.
Setelah output diubah dari yang sebelumya “ya” atau “tidak” menjadi “1” atau “0” kemudian kita harus menentukan ambang batas untuk menentukan ke arah mana independen variabel akan berakhir.
Apabila Anda menentukan ambang batas seperti 0,5 maka independen variabel yang nilainya diatas 0,5 akan berakhir di angka “1” yang dimana artinya prediksi dependen variabel tersebut akan menghasilkan “ya”.
Sebaliknya, apabila indepeden variabel nilainya berada dibawah 0,5 maka independen variabel tersebut akan berakhir di angka “0” yang dimana artinya prediksi variabel dependen tersebut akan menghasilkan “tidak”.
Rumus Logistic Regression
Rumus dari Logistic Regression ini merupakan gabungan dari beberapa rumus yaitu sebagai berikut :
– Rumus Simple Linear Regression atau Multiple Linear Regression
- Simple Linear Regression
y = a + bX
Keterangan :
Y : variabel dependen (respon/prediksi)
a : konstan (titik awal)
b : koefisien (kemiringan garis prediksi)
X : variabel independen (prediktor)
- Multiple Linear Regression
y = b0 + b1X1 + b2X2 + b3X3 + ….. + bnXn
Keterangan :
Y : variabel dependen (respon/prediksi)
b0 : konstan (titik awal)
b1 : koefisien 1 (kemiringan garis prediksi)
b2 : koefisien 2 (kemiringan garis prediksi)
b3 : koefisien 3 (kemiringan garis prediksi)
bn : koefisien ke n (kemiringan garis prediksi)
X1 : variabel independen 1 (prediktor)
X2 : variabel independen 2 (prediktor)
X3 : variabel independen 3 (prediktor)
Xn : variabel independen ke n (prediktor)
– Rumus Fungsi Sigmoid
p = 1/1 + e^-y
Keterangan :
p = probabilitas
e = bilangan euler(2.718)
y = Simple Linear Regression atau Multiple Linear Regression
Rumus fungsi sigmoid ini berguna untuk menghitung probabilitas dari data observasi independen variabel supaya bisa menentukan kearah mana independen variabel tersebut akan berakhir, apakah variabel independen tersebut akan berakhir di angka “0” atau “1” pada variabel dependen.
– Rumus Logistic Regression
ln(p/1-p) = a + bX
Rumus Logistic Regression diatas merupakan rumus untuk membuat garis linear regression yang sebelumnya lurus, menjadi bentuk dari fungsi sigmoid untuk menyesuaikan garis tersebut terhadap bentuk data dari variabel independen dengan variabel dependen yang linear dan sejajar.
Maximum Likelihood
Maximum likelihood merupakan metode yang digunakan dalam Logistic Regression untuk mencari bentuk dari fungsi sigmoid yang terbaik untuk variabel independen dengan variabel dependennya. Cara menghitung Maximum Likelihood adalah sebagai berikut :
Maximum Likelihood = Total perkalian antara independen yang memiliki nilai 1 dan nilai 0 pada dependen variabel
Semakin besar nilai dari Maximum Likelihood maka semakin besar baik pula bentuk dari fungsi sigmoid yang sesuai dengan data variabel independen dengan variabel dependen yang diberikan.
Kode Python Untuk Membuat Model Logistic Regression
- Impor librari
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Impor dataset
dataset = pd.read_csv(‘Social_Network_Ads.csv’)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
- Memisahkan dataset menjadi training set dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
- Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- Latih model Logistic Regression kedalam training set
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
- Memprediksi hasil test set
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
- Memprediksi data observasi baru
print(classifier.predict(sc.transform([[30,87000]])))
note:
Memprediksi data observasi baru berguna untuk mengetahui apakah model yang kita buat sudah akurat atau belum.
- Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
note:
Confusion Matrix merupakan indikator yang digunakan untuk memeriksa apakah model yang kita buat sudah akurat atau belum. Dalam Confusion Matrix ini terdapat matrix yang digunakan untuk mengetahui seberapa banyak prediksi yang didapat oleh model sama dengan hasil dari data observasi aslinya.
Untuk mengukur akurasi model terhadap data yang diberikan, kita dapat menggunakan “accuracy_score”. Accuracy score ini berguna untuk mengetahui seberapa akurat model machine learning dalam memprediksi sebuah data kategorikal atau klasifikasi. Hasil dari accuracy score dinyatakan dalam bentuk persen.
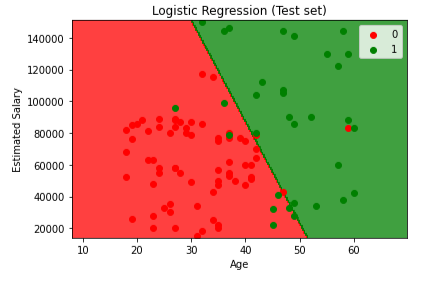
- Visualisasi hasi test set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_test), y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 0.25),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 0.25))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘Logistic Regression (Test set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Semua hal yang sudah dibahas diatas, akan membantu Anda memahami apa itu logistic regression, bagaimana cara kerjanya, bagaimana cara membuatnya dan lainnya supaya Anda bisa membuat model Logsitic Regression yang kuat untuk memprediksi data kategorikal.
Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai 6 tips & tricks mengurangi COGS dan blog kami selanjutnya mengenai K-Nearest Neighbors.
[…] Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai segala hal yang perlu Anda ketahui tentang COGS dan blog kami selanjutnya mengenai Logistic Regression. […]
[…] Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Logistic Regression. Nantikan konten blog kami selanjutnya yang ga kalah […]