Artificial Intelligence For Learning The Basics
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
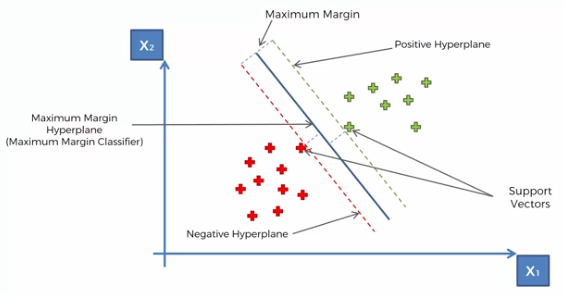
Apa Itu Support Vector Machine?
Support Vector Machine merupakan teknik dalam Machine Learning yang digunakan untuk memisahkan data kategorikal menjadi beberapa kelas dengan cara membuat dan menentukan dimana letak hyperplane yang maksimal.
Support Vector Machine merupakan salah satu model Machine Learning yang kuat karena kemampuan model Support Vector Machine yang bisa membedakan data observasi yang sangat mirip dengan data observasi lain yang akan di kategorikan atau dipisah menjadi kelas yang berbeda.
Hal ini bisa dilakukan oleh Support Vector Machine karena model Support Vector Machine membuat hyperplane yang maksimal dari jarak antara dua vector atau data observasi yang sangat berdekatan, jarak antara dua vector yang berdekatan ini dimakan sebagai margin.
Margin yang maksimal dari kedua vector yang jika disatukan akan menciptakan dan menentukan dimana letak hyperplane yang optimal dalam memisahkan data pada model Support Vector Machine.
Rumus Support Vector Machine
- Rumus Persamaan Hyperplane
w.x + b = 0
Keterangan:
w = vector yang berbobot
x = feature (independen variabel)
b = bias
Note:
Rumus diatas adalah rumus untuk membuat hyperplane berdasarkan vector w, independen variabel dan bias yang merupakan konstanta skalar dan membantu menentukan posisi dari hyperplane tersebut.
- Dot Product
A.B = |A|cosθ * |B|
Keterangan:
|A|cosθ = projeksi vector A terhadap vector B
|B| = jarak vector B
Note:
Dot product berguna untuk mendapatkan nilai skalar dari proyeksi antara 2 vektor. Anda bisa menentukan apakah nilai skalar dari suatu data observasi adalah positif (sebelah kanan) atau negatif (sebelah kiri) dengan cara menentukan jarak dari titik awal vektor B ke hyperplane yang telah dibuat.
Jarak dari titik awal vektor B ke hyperplane yang telah dibuat bisa kita umpamakan sebagai simbol ‘s’ untuk mempermudah perhitungan dan perbandingan nilai.
- Aturan Klasifikasi
- apabila data observasi positif (+1) = w.x + b ≥ 1
- apabila data observasi negatif (-1) = w.x + b ≤ -1
Note:
Ketika nilai skalar yang didapat dari dot product lebih besar dari ‘s’, maka bisa kita katakan bahwa data observasi tersebut berada di sisi kanan hyperplane yang dimana data tersebut masuk kedalam data positif.
Sebaliknya, ketika nilai skalar yang didapat dari dot product lebih kecil dari ‘s’, maka bisa kita katakan bahwa data observasi tersebut berada di sisi kiri hyperplane yang dimana data tersebut masuk kedalam data negatif.
- Persamaan Soft Margin
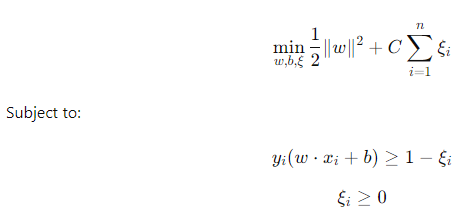
Formula generated by ChatGPT
Keterangan:
||w|| = Panjang vector w
ξ = Variabel Slack
C = Hyperparameter C yang mengontrol besarnya margin dan besarnya pelanggaran margin
Note:
rumus soft margin ini berguna untuk mencari posisi atau titik optimal dari hyperplane dengan cara mengizinkan data observasi untuk melanggar margin atau berada di posisi yang salah. Misalnya data observasi positif berada di area data negatif atau data observasi negatif berada di area data positif.
Anda juga bisa mengatur besar kecilnya hyperparameter C yang bisa menentukan besar atau kecilnya margin dari hyperplane sesuai dengan kebutuhan data yang didapat.
Nilai dari hyperparameter C yang tinggi membuat margin dari hyperplane semakin kecil atau minimal, hal ini dilakukan untuk meminimalkan pelanggaran margin tetapi kekurangannya adalah model bisa menjadi overfit.
Sebaliknya dari hyperparameter C yang rendah membuat margin dari hyperplane semakin besar atau maksimal, hal ini dilakukan untuk melakukan generalisasi terhadap data observasi supaya model bisa memprediksi data baru dengan lebih baik tetapi kekurangannya adalah pelanggaran margin menjadi semakin banyak.
Kode Python Untuk Membuat Model Support Vector Machine
- Impor Librari
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Impor dataset
dataset = pd.read_csv(‘Social_Network_Ads.csv’)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
- Membagi dataset menjadi training set dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
- Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- Melatih model Support Vector Regression kedalam training set
from sklearn.svm import SVC
classifier = SVC(kernel = ‘linear’, random_state = 0)
classifier.fit(X_train, y_train)
- Memprediksi hasil test set
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
- Memprediksi data observasi baru
print(classifier.predict(sc.transform([[30,87000]])))
- Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
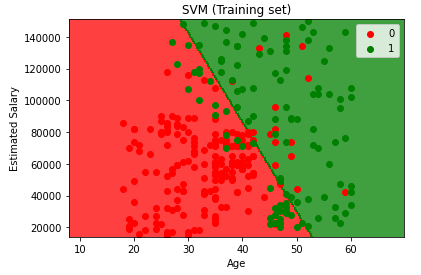
- Visualisasi hasil training set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_train), y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 0.25),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 0.25))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘SVM (Training set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
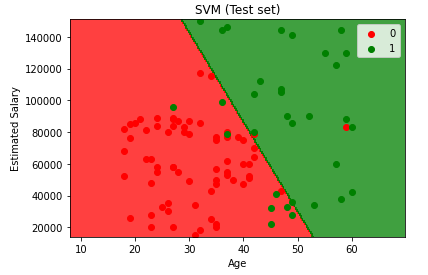
- Visualisasi hasil test set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_test), y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 0.25),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 0.25))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘SVM (Test set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Setelah membaca materi yang telah disampaikan diatas, Anda bisa mengetahui apa itu Support Vector Machine, bagaimana cara kerjanya, apa rumus yang harus diperhatikan dalam model Support Vector Regression dan bagaimana cara membuat modelnya dengan kode pyhton sehingga Anda bisa memprediksi suatu data linear maupun non-linear.
Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai K-Nearest Neighbor dan blog kami selanjutnya mengenai kernel Support Vector Machine.
[…] Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Logistic Regression dan blog kami selanjutnya mengenai Support Vector Machine. […]
[…] Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Support Vector Machine. Nantikan konten blog kami selanjutnya yang ga kalah […]