Artificial Intelligence For Learning The Basics
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Apa Itu Kernel Support Vector Machine?
Kernel Support Vector Machine atau yang bisa kita sebut sebagai kernel SVM adalah model yang sama dengan Support Vector Machine, yang membedakannya yaitu Support Vector Machine pada umumnya memisahkan atau mengklasifikasikan data secara linear sehingga membentuk dua kelas yang berbeda secara linear.
Kernel SVM digunakan ketika data yang akan dilatih dan diprediksi adalah data yang tidak bisa dipisahkan atau diklasifikasi secara linear atau non-linear seperable.
Pada dasarnya, cara yang dilakukan untuk memisahkan atau mengklasifikasi data non-linear adalah dengan memetakan data tersebut ke dimensi yang lebih tinggi.
Rumus Yang Digunakan Dalam Kernel Support Vector Machine
- Mapping Function
z = x^2 + y^2
f(x,y) = (x,y,z)
f(x,y) = (x,y, x^2 + y^2)
Keterangan:
x = independen variabel
y = dependen variabel
z = dimensi baru untuk memetakan data menjadi 3 dimensi
- Kernel Gaussian Radial Basis Function (RBF)
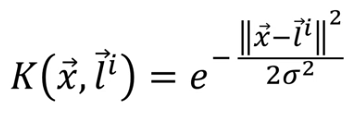
Formula generated by ChatGPT
Keterangan:
K = kernel
x = variabel independen
l = landmark
e = eksponensial
σ = gamma
K(x,y) = vektor x dan vektor y dari kernel
||x – l||^2 = jarak Euclidean antara vektor x (independen variabel) dengan vektor l (landmark)
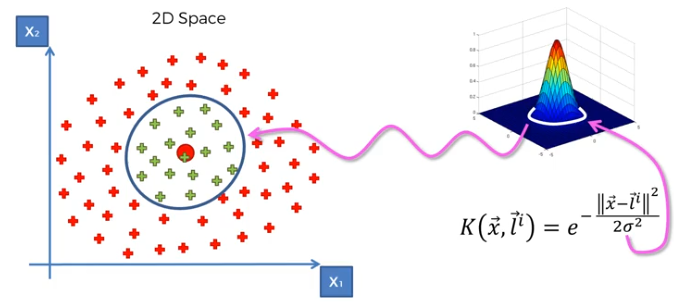
Cara Memisahkan Data Non-Linear Dengan Ruang Dimensi Yang Lebih Tinggi
- Petakan data yang berada di 2 dimensi (2D) menjadi data yang berada di 3 dimensi (3D) dengan menggunakan rumus fungsi pemetaan atau mapping function,
- Setelah data berada di ruang 3 dimensi, akan terlihat ada data yang terpisah berdasarkan klasifikasinya,
- Buatlah ruang hyperplane pada ruang 3 dimensi tersebut untuk memisahkan data (ruang hyperplane sama dengan hyperplane yang berbentuk garis pada ruang 2 dimensi),
- Setelah ruang hyperplane ditempatkan, kembalikan ruang 3 dimensi tersebut menjadi ruang 2 dimensi untuk melihat pemisahan atau klasifikasinya di ruang 2 dimensi,
- Setelah kembali ke ruang 2 dimensi, data akan terlihat terpisah secara non-linear berdasarkan data yang diberikan.
Note:
Kelemahan dari memisahkan data dengan ruang dimensi yang lebih tinggi adalah komputasi komputer yang tinggi karena prosesnya yang membuat ruang yang lebih tinggi sehingga membutuhkan kekuatan komputasi yang tinggi dan hal ini bisa menyebabkan melambatnya performa komputer atau laptop Anda.
Karena komputasi yang tinggi, didapat lah cara alternatif supaya tidak menggunakan komputasi yang tinggi yaitu dengan cara kernel SVM. Kernel SVM ini dilakukan dengan cara mengkalkulasi data observasi kedalam rumus supaya didapatkan pemisahan data atau boundary yang non-linear.
Cara memisahkan Data Non-Linear Dengan Kernel SVM
- Tentukan landmark atau titik tengah dari data yang akan dipisah atau diklasifikasi,
- Hitung seberapa besar jarak antara data observasi dengan titik landmark dengan cara mengurangi jarak dari data observasi ke titik landmark,
- Tentukan gamma dari data observasi untuk mengukur sebarapa besar batas dari ruang hyperplane untuk memisahkan data atau mengklasifikasikan data,
- Nilai yang sudah didapat dari poin nomor 2 sampai poin nomor 4 dimasukkan kedalam rumus kernel Gaussian Radial Basis Function (RBF),
- Nilai eksponensial dari kernel yang mendekati angka 0 akan berada diluar batas (negatif) dan nilai yang mendekati angka 1 akan berada di dalam batas (positif)
Note:
Data observasi yang berada diluar batas kernel termasuk kedalam klasifikasi data negatif. Sebaliknya, data observasi yang berada didalam batas kernel termasuk kedalam klasifikasi data positif.
Data observasi negatif dan data observasi positif bukan berarti mereka memiliki nilai data observasi yang negatif ataupun positif tetapi hanya mengelompokkan data berdasarkan batas kernel yang didapat dari rumus kernel Gaussian RBF untuk memisah atau mengklasifikasi data yang tidak bisa dipisah secara linear.
Kode Python Untuk Membuat Model Kernel Support Vector Machine
- Impor library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- Impor dataset
dataset = pd.read_csv(‘Social_Network_Ads.csv’)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
- Memisahkan data menjadi training set dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
- Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- Melatih model kernel SVM kedalam training set
from sklearn.svm import SVC
classifier = SVC(kernel = ‘rbf’, random_state = 0)
classifier.fit(X_train, y_train)
- Memprediksi hasil test set
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
- Memprediksi data baru
print(classifier.predict(sc.transform([[30,87000]])))
- Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
- Visualisasi hasil training set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_train), y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 0.25),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 0.25))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘Kernel SVM (Training set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
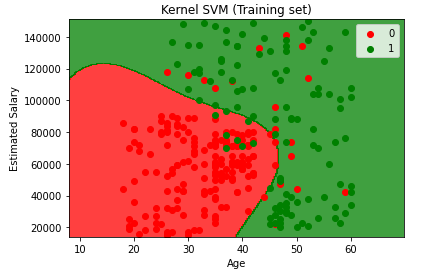
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
- Visualisasi hasil test set
from matplotlib.colors import ListedColormap
X_set, y_set = sc.inverse_transform(X_test), y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() – 10, stop = X_set[:, 0].max() + 10, step = 0.25),
np.arange(start = X_set[:, 1].min() – 1000, stop = X_set[:, 1].max() + 1000, step = 0.25))
plt.contourf(X1, X2, classifier.predict(sc.transform(np.array([X1.ravel(), X2.ravel()]).T)).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap((‘red’, ‘green’)))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap((‘red’, ‘green’))(i), label = j)
plt.title(‘Kernel SVM (Test set)’)
plt.xlabel(‘Age’)
plt.ylabel(‘Estimated Salary’)
plt.legend()
plt.show()
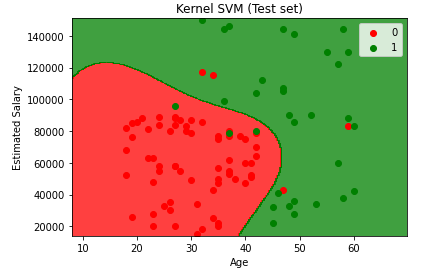
Plot by Kirill Eremenko & Hadelin de Ponteves on Udemy
Kernel SVM sangat berguna ketika Anda ingin memprediksi data yang tidak bisa dipisah secara linear dan dengan data yang agak lebih kompleks. Ikuti langkah – langkah dan cara membuat model kernel SVM diatas supaya Anda mengetahui bagaimana cara kerja model kernel SVM dan bagaimana cara membuat modelnya.
Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai Support Vector Machine dan blog kami selanjutnya mengenai Naive Bayes.
[…] Bagi anda yang ingin memberikan komentar pada website ini, silahkan tulis komentar Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai K-Nearest Neighbor dan blog kami selanjutnya mengenai kernel Support Vector Machine. […]
[…] Anda dengan mengisi nama dan alamat email Anda. Anda dapat membaca blog kami sebelumnya mengenai kernel SVM. Nantikan konten blog kami selanjutnya yang ga kalah […]